对26262的分析:汽车软件中机器学习及安全
机器学习在自动驾驶中扮演着越来越重要的角色,然而,它是否足够安全仍然存在争议。ISO 26262道路车辆功能安全标准为确保安全提供了一套全面的要求,但没有解决基于机器学习软件的独特特性。在这篇文章中,作者在几个方面提出了一些建议,以解决这一问题。
1简介
在软件开发的许多领域,机器学习的使用越来越多,汽车软件开发也不例外。高级驾驶员辅助系统和自动驾驶系统是机器学习发挥重要作用的两个领域。ISO 26262等标准的出现有助于集中行业实践,以系统且一致的方式解决安全问题。但是,ISO 26262的设计并没有考虑到机器学习这样的技术,这就造成了创新和提高安全性之间的矛盾。
针对这一问题,在几个领域进行了积极的研究。最近,人们从理论和实践两方面分析了一般机器学习方法的安全性。然而,大多数研究都是专门针对神经网络的。支持神经网络验证和确认(V&V)的工作出现在20世纪90年代,其重点是通过提取更容易理解的表示,使其内部结构更容易评估。还提出了神经网络的一般V&V方法。最近,随着深度神经网络的普及,验证研究包括了更多的主题,如生成深度神经网络预测的解释,提高分类的稳定性和深度神经网络的属性检查。
尽管存在挑战,神经网络已经在高保障系统中得到了应用,神经网络的安全认证也得到了一些关注。Pullum等人的给出了详细的指导V&V,以及其他方面的安全评估,如危害分析与重点在航空航天领域的自适应系统。贝德福德等人。防御在任何安全标准中寻址神经网络的一般要求。Kurd等人建立了神经网络在安全情况下使用的标准。
最近对自动驾驶系统兴趣的激增也推动了对认证的研究。Koopman和Wagner确定了认证的一些关键挑战,包括机器学习。ML. Martin分析了ISO 26262对于自动驾驶系统的合适程度,但是关注的是它所增加的复杂性所带来的影响,而不是机器学习的具体使用。Spanfelner从驾驶员辅助系统的角度评估了ISO 26262。最后,Burton等人研究了使用机器学习组件的自动驾驶系统所需要的安全案例。本论文的贡献是对上述研究的补充。我们分析了使用基于机器学习的软件对ISO 26262各个部分的影响。特别地,我们考虑了它在危害分析领域和软件开发过程阶段的影响,确定了使用机器学习产生的不同问题,并通过对标准的更改和进一步的研究对解决这些问题的步骤提出了建议。
2背景
2.1 ISO 26262
ISO 26262是规范道路车辆功能安全的标准。它建议使用危害分析和风险评估(HARA)方法来识别系统中的危险事件,并指定减轻危害的安全目标。该标准有10个部分,本篇论文只关注第6部分:“软件层面的产品开发”。该标准遵循下图中众所周知的V模型。
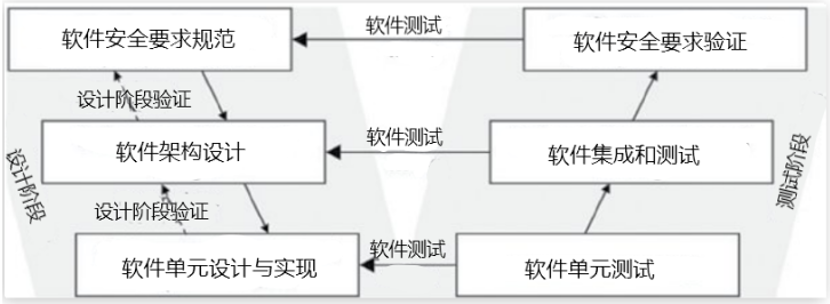
软件层面的产品开发
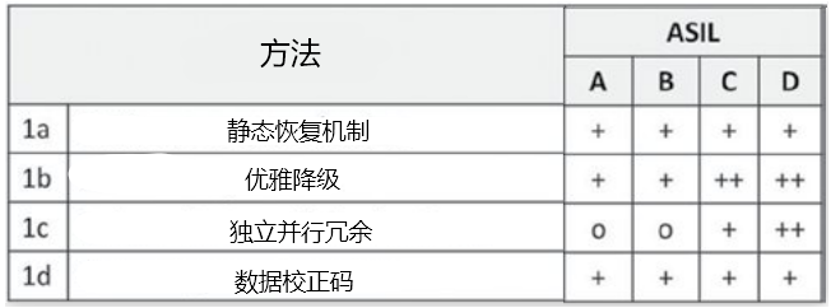
汽车安全完整性等级(ASIL)是在ISO 26262中为汽车系统提出的风险分类方案。ASIL代表降低项目风险所需的严格程度,其中ASIL D代表最高,ASIL A代表最低风险。标准的第6部分详细说明了软件开发的遵从性要求。例如,图2显示了架构设计中推荐使用的错误处理机制。一种方法的推荐度取决于ASIL,其分类如下:++表示强烈推荐ASIL的方法;+表示推荐用于ASIL的方法; o表示该方法不建议使用或不建议使用ASIL。例如,优雅降级(1b)是ASIL C项的唯一推荐机制,而ASIL D项也适合独立的并行冗余(1c)。
在软件架构级别上的错误处理机制
2.2机器学习
在本文中,我们关注的是使用机器学习的软件实现,机器学习组件是使用监督、非监督或强化学习方法的训练模型。在功能性安全保障方面,在线学习的关键弱点是不能提前提出和评估安全论证。所以对于汽车系统中的机器学习组件,我们假设在线学习仅限于安全性要求不高的功能。例如,机器学习组件在线训练以了解司机的信息娱乐偏好。因此,对于本文所讨论的机器学习应用程序,我们假设训练是离线进行的。
机器学习有几个特征会影响安全性或安全性评估。
不透明性:。增加机器学习模型的表达能力通常是以牺牲透明性为代价的,许多研究工作致力于在保证表达能力的同时使模型更透明。不透明是安全保障的一个障碍,因为评估人员更难以确定模型是否按预期运行。
错误率:机器学习模型通常不能很好地运行,并且有一定的错误率。此外,虽然真实错误率的估计值是机器学习过程的输出,但是这个估计值的可靠性只有统计上的保证。最后,即使真实错误率的估计值是准确的,它也不能反映系统在输入一组数据后实际运行时的错误率,因为真实误差是基于一组样本的。使用机器学习组件设计安全系统时必须考虑这些特性。
训练集:基于监督和非监督学习的机器学习模型使用可能遇到的行为的子集进行训练。因此,训练集必然是不完整的,甚至不能保证它能反映可能的输入空间。随着时间的推移,操作环境中输入的基本分布可能会偏离训练集的分布,从而降低安全性.
不稳定性:更强大的机器学习模型(例如,深度神经网络)通常使用局部优化算法进行训练,并且可以有多个优化。因此,即使训练集保持不变,训练过程也可能产生不同的结果。这种特性使得调试模型或重用以前的安全评估部分变得困难。
3对ISO 26262的分析
在本节中,我们将详细分析机器学习对ISO 26262的影响。由于基于机器学习的软件是一种特殊类型的软件,我们将标准中与软件相关的部分划分为受影响的部分,对基于机器学习的软件的处理应区别于现有的软件处理。从26262标准的十个部分的两个部分(概念阶段危害分析和软件开发阶段)中确定了受影响的五个方面。我们下面描述了五个方面的影响与相应的建议。
3.1 危险识别
ISO 26262将危害定义为“当危害是身体伤害或对人的健康造成损害时,该物品的功能失常行为所造成的潜在伤害来源”。机器学习的使用会产生新的危害。一种危害类型是操作员认为自动化程序辅助(通常使用机器学习)比实际的更智能,从而变得自满。例如,驾驶员在自动转向功能中停止监视转向。
基于强化学习的组件可能会对环境产生负面影响,以实现其目标。例如,为了更快地到达目的地,自动驾驶系统可能会违反法律;自动驾驶系统可以通过利用某些传感器漏洞来“看”自己离其他车辆有多近,从而避免因与其他车辆靠得太近而受到罚款。尽管这样的危害可能是机器学习组件独有的,但它们可以追溯到故障,因此它们符合ISO 26262的现有准则。
对ISO 26262的建议:应将危害预防范围扩大,包括人与车辆之间复杂的行为交互可能造成的危害,而这些行为交互不是由于系统故障造成的。
3.2 故障和失效模式
ISO 26262要求使用诸如故障模式影响分析(FMEA)之类的分析来确定故障如何导致危害。不同于一般的软件,很多故障是机器学习独有的。神经网络的具体故障类型和模式已经被编目。如网络拓扑结构和学习方法的错误,导致泛化能力差(如层间连通性不够,学习速率过高,等等)或者错误的训练集。
虽然机器学习故障有一些独特的特征,但这并不能说明失效模式。机器学习 故障仅增加所部署组件的错误率,从而导致一种特定类型的故障——某些输入的输出不正确。但是,由于大多数软件故障以给定输入的不正确输出的形式出现,我们可以得出这样的结论:机器学习组件的故障分析与已编程组件没有什么不同,现有的ISO 26262建议也适用。
针对ISO 26262的建议:机器学习故障的独特类型为开发有针对性的工具和技术提供了机会,以帮助机器学习模型发现故障。例如,Chakarov等人描述了一种用于调试错误分类的技术,而Nushi等人提出了一种解决由于链接的机器学习组件之间的复杂交互而导致的故障的方法。随着这些技术的成熟,应该对ISO 26262进行修改,要求对机器学习组件使用这些技术。
当功能很复杂并且汽车安全完整性等级很高(例如,在更高的自动化级别上),只有通过增加或改进训练集,错误率才可能达到一个可接受的低水平。应该需要专门的体系结构技术来帮助减轻机器学习故障和故障的影响。
3.3 规范和验证
ISO 26262的建议: 高ASIL组件实现所需要的方法应该基于功能的可指定性。对于完全专门化的功能,必须进行编程。对于不允许完全指定的功能(例如,感知),应该允许使用基于机器学习的方法,并且必须放宽完全指定的要求。但是,即使在这种情况下,仍应尽可能在有限的能力范围内使用专门化。为架构级分配的机器学习组件(即,在进行单位级别的细化之前)可以完整地指定并跟踪到危害。例如,一个组件可能要求“识别行人”,以避免自动驾驶汽车伤害他们。
在组件单元设计级别,可以指定对样本数据的要求,以确保获得适当的培训、验证和测试集。随后,收集到的数据可以针对这一具体情况进行验证。来自黑盒软件测试的技术,如输入域分区,可能会有帮助。例如,行人分类器的输入域可以按年龄类别、姿势(如站立、倾斜等)、服装类型等进行划分。数据需求可以指定来自每个分区的样本的相对数量,以确保样本数据的覆盖率和代表性。
最后,尽管不可能实现完整的行为规范,但是部分规范仍然可能实现。例如,如果行人身高必须小于9英尺,那么可以使用此属性来过滤误报。这些特性可以合并到培训过程中,或者在培训后对模型进行检查。其中一些建议可能会在即将发布的OMG标准中涉及到传感器和感知问题[37]。
因为机器学习组件是从固有的不完整数据集中训练出来的,所以它们违反了基于V模型的流程中组件功能必须完全指定,且修改是可验证的的假设。此外,机器学习非常适合的某些类型的高级功能(例如,需求感知)在原则上可能是未知的。因此,机器学习组件在设计时就预知有错误率,并且会周期性地失败。相比取消此类功能,建议ISO 26262根据功能是否可指定提供不同的安全要求。
3.4 机器学习的使用标准
机器学习可以用来实现整个软件系统,包括它的架构,使用端到端方法。例如Bojarski等人训练深度神经网络直接从原始传感器数据中做出适当的转向指令,避开典型的自动驾驶系统架构组件,如车道检测、路径规划等。
在这里,我们可以假设单元级别,在传统意义上是独立于体系结构开发的不同组件。在这种情况下,有可能将训练模型的结构提取并解释为由具有不同功能的单元组成,因为这种结构在训练过程中是突现的,是不稳定的。如果用一个稍微不同的训练集对模型进行再训练,这个结构可以任意改变。值得注意的是,深度神经网络确实具有不同意义上的体系结构——一组层及其连接。然而,由于实际“实现”所需功能的是培训,所以此体系结构更像是一个通用的执行层。因此,端到端方法极大地挑战了ISO 26262的基本假设。
端到端方法的另一个挑战是,在某些情况下,训练集的大小需要比使用[39]的编程体系结构时大得多。这增加了本已具有挑战性的问题的压力,即为安全关键的环境获取足够的培训集。
最后,如果组件太复杂,在组件级别使用机器学习时,端到端方法也会出现问题。例如,在一个极端,体系结构可以由单个组件组成。ISO 26262通过强制使用模块化原则(如限制组件的大小和最大化组件内的内聚性)来防止这一缺陷。但是,机器学习组件缺乏透明性会妨碍评估组件复杂性的能力,从而影响应用这些原则。幸运的是,提高机器学习的透明度是一个活跃的研究领域。
ISO 26262的建议:通过使用端到端方法,机器学习可以在体系结构级别与系统一起广泛使用,或者仅在组件级别使用。端到端方法挑战了这样一种假设,即将复杂系统建模为一种具有各自功能的组件的稳定层次分解。这限制了对系统安全的大多数技术的使用,因此我们建议ISO 26262只允许在组件级别使用机器学习。
3.5 需要的软件技术
ISO 26262要求在软件开发生命周期的不同阶段使用许多专门的技术。我们的分析表明,其中一些仍然适用于机器学习组件,而其他一些可以很容易地进行调整,但是仍然有许多技术特别倾向于使用命令式编程语言实现代码的。为了消除这种偏见,在不影响安全性的情况下,应该用技术的意图和成熟度来表达需求,而不是用技术的具体细节来表达需求。
- 用户评论