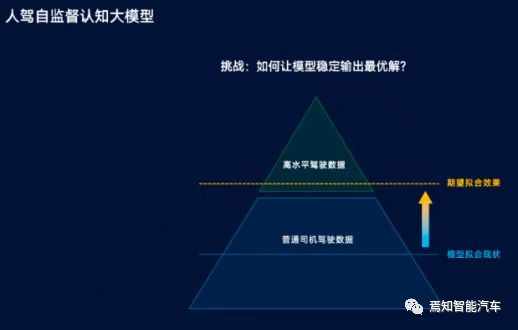
在数字系统中,模拟信号将会转化成数字序列(以位的形式)。这种位序列我们称之为“数据流”。单个位的位置变化也会导致数据输出中的灾难性的错误。几乎在所有的电子设备中,我们都会发现错误并使用错误检测和修正技术来获得准确或近似的输出。
数据在传输(从源头到接收器)期间可能会损坏。它可能会受到外部噪声或者其他一些物理缺陷的影响。在此种情况下,输入数据和接收到的输出数据不同。这种不匹配的数据称之为“错误-Error“。数据错误将导致重要/安全数据的丢失。即使数据中的一点点变化都可能影响整个系统的性能。通常,数字系统中的数据传输将采用”位传输-Bit Transfer“的形式。在此种情况下,数据错误很可能在 0 和 1 的位置发生变化。
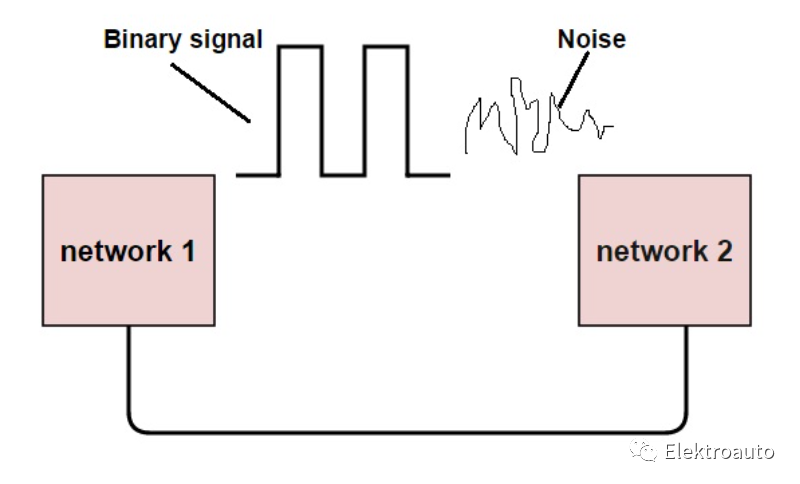
错误的类型
在一个数据序列中,如果1变0或者0变1,称之为“误码- Bit Error”。
在从发送器到接收器的数据传输过程中,通常会发生三种类型的错误:
单位错误 - Single Bit Errors;
多位错误 - Multiple Bit Errors;
突发错误 - Burst Errors;
Single Bit Data Errors
整个数据序列中1位的变化称为“单比特错误”。单比特错误在串行通讯系统中是非常少见的,这种错误只发生在并行通讯系统中,因为数据是在单线中按位传输的,单线有可能产生噪声。
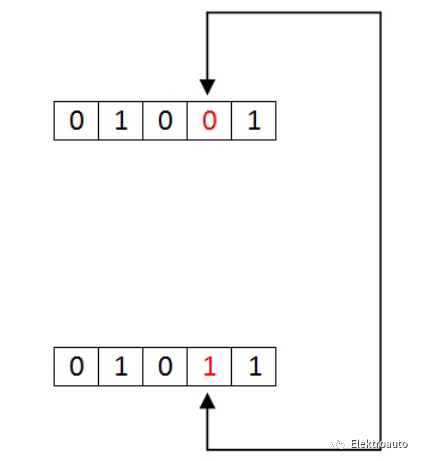
如果从发送器到接收器的数据序列中的两位或更多位发生变化,则称之为“多位错误”。这种类型的错误发生在串行类型和并行类型的数据通讯网络中。
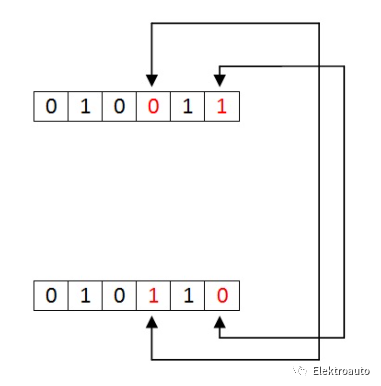
数据序列中比特组的变化称为“突发错误”。突发错误是从第一个比特变化到最后一个比特变化计算的。
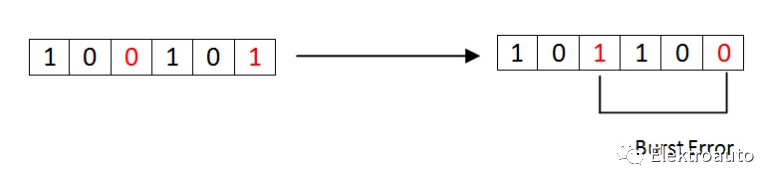
上图中,我们识别从第3位到第6位的错误。第3位到第6位之间的数字也被视为错误。这些位集称为“突发错误”。这些突发错误在发送器和接收器之间发生变化,这可能会导致数据序列出现重大错误。这种类型的错误发生在串行通讯中并且很难解决。在数字通信系统中,错误与数据一起从一个通信系统传输到另一个通信系统。如果不检测和纠正这些错误,数据将丢失。为了进行有效的通信,数据的传输应该具有很高的准确性。这可以通过首先检测错误然后纠正它们来实现。错误检测是在通信系统中检测从发送器传输到接收器的数据中存在的错误的过程。我们使用一些冗余码来检测这些错误,通过在数据从源传输时添加到数据中(发射器)。这些代码称为“错误检测代码”。
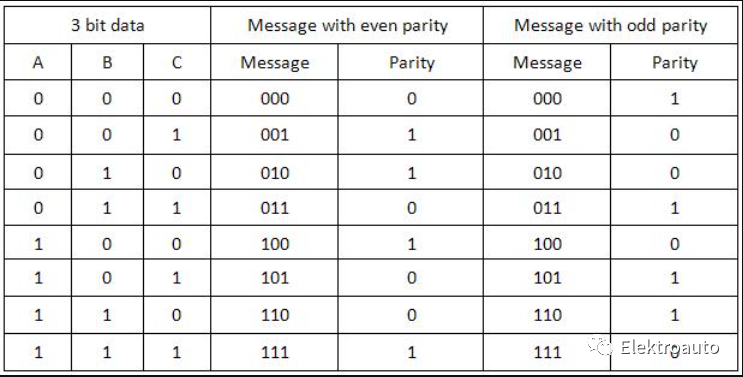
奇偶校验位只是在发送数据之前在发送器处添加到数据中的附加位。在添加奇偶校验位之前,计算数据中 1 或 0 的数量。基于这种数据计算,额外的位被添加到实际信息/数据中。在数据中加入奇偶校验位会导致数据串大小发生变化。这意味着如果我们有一个 8 位的数据,那么在数据二进制串中添加一个奇偶校验位后,它将成为一个 9 位的二进制数据串。奇偶校验也称为“垂直冗余校验-Vertical Redundancy Check(VRC)”。
偶校验 Even Parity;
奇校验 Odd Parity;
如果数据有偶数个 1,则奇偶校验位为 0。例如:数据为 10000001 -> 偶校验位 01 的奇数,偶校验位为 1。例如:数据为 10010001 -> 偶校验位 1如果数据有奇数个 1,则奇偶校验位为 0。例如:数据为 10011101 -> 奇校验位 0偶数1,奇校验位为1。例如:数据为10010101 -> 奇校验位1在发送端为数据添加奇偶校验位的电路称为“奇偶校验发生器”。奇偶校验位被发送并在接收器处进行检查。如果发送器发送的奇偶校验位和接收器接收的奇偶校验位不相等,则检测到错误。在接收端检查奇偶校验的电路称为“奇偶校验器- Parity Check”。
循环码是一种线性(n,k)块码,其特性是一个码字的每一次循环移位都会产生另一个码字。这里 k 表示发送器的消息长度(信息比特数)。n 是添加校验位后的消息总长度。(实际数据和校验位)。n,k 是校验位的数量。在那里通过错误检测进行循环冗余校验的代码称为CRC码(循环冗余校验码),循环冗余校验码是缩短的循环码。这些类型的代码用于错误检测和编码。它们可以使用带有反馈连接的移位寄存器轻松实现。这就是为什么它们被广泛用于数字通信中的错误检测。CRC 代码将提供有效和高水平的保护。根据所需的位检查次数,我们将在实际数据中添加一些零 (0)。这个新的二进制数据序列除以长度为 n + 1 的新字,其中 n 是要添加的校验位的数量。作为该模 2 除法的结果获得的提醒被添加到被除数位序列以形成循环码。生成的代码字完全可以被代码生成中使用的除数整除。这是通过发射器传输的。
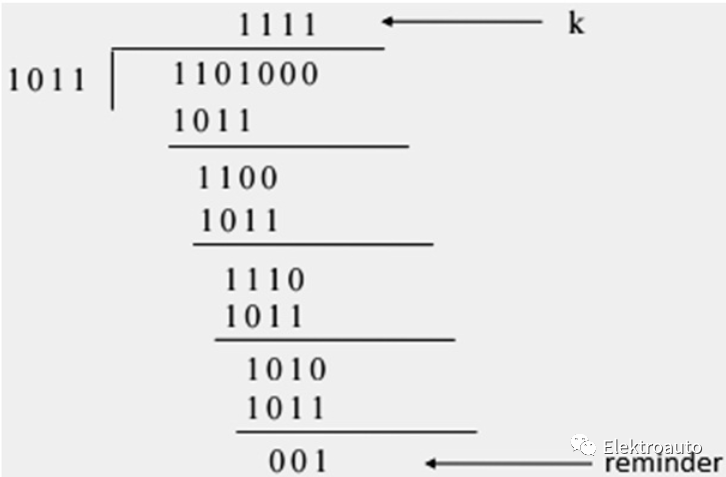
在接收端,我们将接收到的码字用相同的除数相除,得到实际的码字。对于无错误接收数据,提醒为0。如果提醒为非零,则表示接收的代码/数据序列中存在错误。错误检测的概率取决于用于构造循环码的校验位 (n) 的数量。对于长度为 n - 1 的突发错误,错误检测的概率为 100%。长度等于 n + 1 的突发错误,错误检测的概率降低到 1 - (1/2) n-1次方。长度大于 n - 1 的突发错误,错误检测的概率为 1 - (1/2) n次方。在纵向冗余方法中,BLOCK 位以表格格式(按行和列)排列,我们将分别计算每一列的奇偶校验位。这些奇偶校验位的集合也与我们的原始数据位一起发送。纵向冗余校验是逐位计算奇偶校验,因为我们单独计算每一列的奇偶校验。这种方法可以很容易地检测出突发错误和单比特错误,而不能检测出同一垂直切片中发生的2比特错误。
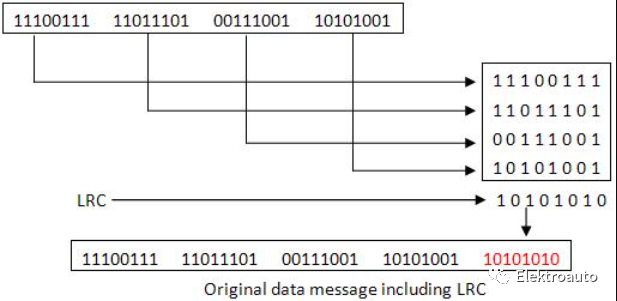
校验和类似于奇偶校验位,不同之处在于和中的位数大于奇偶校验并且结果总是被限制为零。这意味着如果校验和为零,则检测到错误。消息的校验和是一定长度的码字的算术和。总和通过 1 的补码表示,并作为实际代码字的代码扩展存储或传输。在接收器处,通过接收来自发送器的位序列来计算新的校验和。校验和方法包括奇偶校验位、校验位和纵向冗余校验(LRC)。例如,如果我们必须为一个长数据序列(也称为数据串)传输和检测错误,那么我们将它分成较短的字,我们可以用相同宽度的字存储数据。对于每个另一个传入位,我们会将它们添加到已存储的数据中。在每种情况下,新添加的词都称为“校验和”。在接收端,接收到的比特校验和与发送端的校验和相同,没有发现错误。我们还可以通过添加所有数据位来找到校验和。例如,如果我们有 4 个字节的数据为 25h、62h、3fh、52h。在接收端,要检查数据是否正确接收,只需将校验和与实际数据位相加即可(我们将得到 200H)。通过丢弃进位半字节,我们得到 00H。这意味着校验和被限制为零。所以数据没有错误。
举个例子:
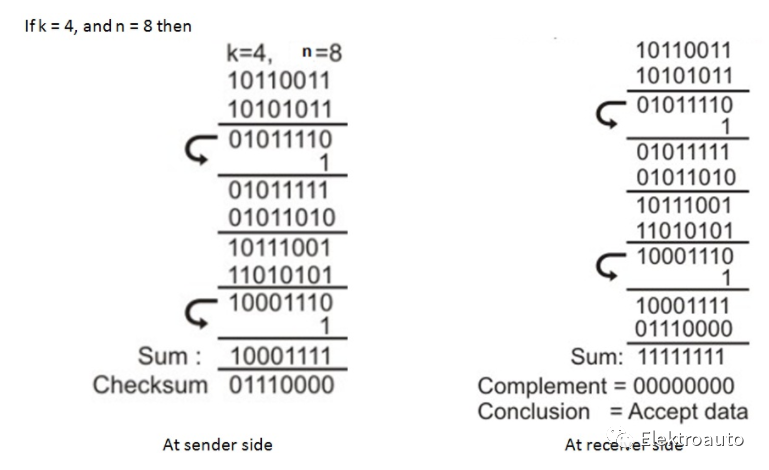
到目前为止,我们讨论了错误检测代码。但是要接收准确、完美的数据序列而没有任何错误,仅通过检测数据中发生的错误是不够的。但我们也需要通过消除错误的存在来纠正数据,如果有的话。为此,我们使用了一些其他代码。用于检错和纠错的代码称为“纠错码”。纠错技术有两种类型。 分别是:纠正单个比特错误的过程或方法称为“单个比特纠错”。检测和纠正数据序列中突发错误的方法称为“突发纠错”。