工具列表
Tool list
Synopsys Coverity专家:在软件缺陷检测中如何做到游刃有余?(上)

作者:Synopsys技术顾问-Johnny Huang
随着软件开发流程的逐步成熟,IT公司在产品的安全测试这块领域投入精力和财力越来越大。尽早地在产品开发周期(Software Development Life-Cycle: SDLC)中发现安全缺陷,也在越来越多的软件公司和互联网公司获得共识。
要在产品开发周期中尽可能多的发现安全缺陷,一款强有力的源代码检测工具必不可少。Coverity因其出色的源代码检测能力和缺陷管理能力,成为众多IT公司的首选。作为一名Synopsys的技术顾问,在与客户的交流的过程中,发现虽然许多公司花了不少精力在Coverity上,但或多或少的存在以下几个误区,导致Coverity的效能没有最大地发挥出来,并且走了不少弯路。本文将这几个误区整理出来,供使用Coverity的相关人员参考。如果你是Coverity老用户,可以参考这五个误区对Coverity的系统环境做优化,提高项目的整体开发效率;如果你是Coverity新用户,可以对这五个误区多做熟悉,在正式部署和使用Coverity的时候绕开这五大误区,避免走弯路。
误区一:
过于频繁对代码扫描提交

典型误用场景一
将Coverity集成到公司的SDLC后,设定固定周期对代码扫描提交,周期小于一天。
典型误用场景二
开发人员将代码提交到代码库后即触发Coverity的扫描提交。
解读
为什么频繁扫描提交不值得?
首先是时间。如果一个项目的本来编译时间就长达数小时,加入Coverity后,由于Coverity对项目原生编译命令的捕获以及再次编译,耗费时间比原来的时间更长。如果过于频繁扫描,尤其是在工作时间想通过Coverity的扫描分析得出的结果立即修复缺陷,将浪费不少的开发资源。
其次是空间。笔者做过测试,基于Android 8.0系统的原生代码扫描,将同一份扫描结果提交到Coverity Connect若干次。结果显示,初次提交将在Connect中产生2.3GB的数据,以后每次提交将产生300MB左右的数据。由此数据可以看出,就算没有引入新缺陷,Connect在对每次提交的快照(snapshot)做增量存储之后,还是会对数据库产生不小的数据压力。基于此,过于频繁提交非但没有带来收益,反而影响了数据库的性能。
推荐做法一:合理调配Coverity的缺陷扫描时间,推荐的周期长度最好大于等于1天,小于等于1周。间隔小于一天,由于代码增量不大,扫描出来的缺陷不多或者根本没有新增缺陷,从而浪费了Coverity资源。如果间隔过大,超过一周,代码增量过大,可能会导致新增缺陷过多,从而给开发人员一下子增加不少工作。
这里说的合理的扫描周期,比如通过将Coverity集成到开发流程之后,将Coverity的分析扫描时间设置到夜间。分析扫描在夜间做完后,开发人员在第二天查看缺陷报告,修复缺陷。也有客户将扫描时间设置为隔天,即周二、周四、周六,这也不失为一个合理的周期。
推荐做法二:如果开发人员想在代码提交前用Coverity做分析缺陷,待缺陷修复后再提交代码,这里推荐使用Coverity的桌面分析,可以帮助开发人员快速分析文件中的缺陷,并且不对Analysis服务器和Connect服务器产生压力。
误区二:
未对Coverity Analysis和Connect做合理部署
典型误用场景
找一台闲置的编译机,将Coverity Analysis和Connect放在同一台服务器中。项目的编译(Build),分析(Analysis),提交(Commit),缺陷入库都在此服务器中。
解读
Coverity Analysis和Connect是典型的C/S架构,Coverity Analysis对项目代码进行扫描分析后,将缺陷扫描的结果提交到Connect做集中管理。其中Coverity Analysis作为客户端(Client)需要依赖项目的编译环境,即要成功做完一次Coverity 的编译分析,必须保证项目能够被完整的成功编译。Coverity Analysis一般推荐客户用闲置的编译机或者一台已经配好的具有项目编译环境的服务器。而Coverity Connect作为服务器(Server),将对所有提交到其上的缺陷建立数据库做统一管理,Coverity Connect的管理员和用户可以登录到Coverity Connect界面来对用户和缺陷做管理维护。
首先,因其Coverity Analysis和Connect所依赖的环境完全不一样,所以将其放在同一台服务器完全是没必要的。不仅如此,此举还会导致Coverity Analysis 和Connect互相抢占服务器资源,影响各种的性能,从而导致用户体验下降。
其次,选择合理配置的服务器来对Coverity的分析扫描和Coverity数据库做支撑是非常必要的,这些配置包括CPU,内存和硬盘大小。如果因为一开始对配置选择的不合理而来对Coverity做迁移,那将耗费不少额外的精力和时间,得不偿失。
推荐做法:在部署Coverity Connect之前咨询Coverity技术人员选取合适的配置的服务器分别部署Coverity Analysis和Coverity Connect。将在日后的Coverity维护中省时省力。
误区三:
把Coverity当成代码管理工具
典型误用场景
尝试在Coverity Connect中获取项目代码各版本变化
解读
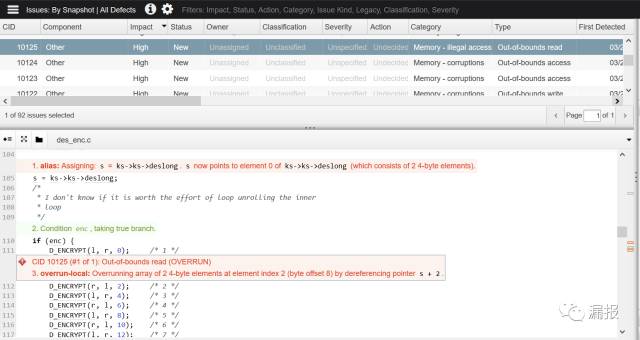
Coverity Connect作为一款出色的缺陷管理工具,对缺陷的引入过程都通过Connect界面在代码里一一做呈现(如图)。这意味着Connect的数据库会保存项目代码。为了节省数据库空间,Connect的数据库保存项目代码是做覆盖保存的,即在Connect看到的是缺陷引入的最新一个版本的副本。所以将Coverity Connect这个缺陷管理工具作为代码管理工具是不可取的,如果需要获取代码的各版本变化,建议直接使用git, svn这类专业的代码管理工具才能达到用户的目的。
误区四:
混淆项目(project)和数据流(stream)
典型误用场景
配置project和stream为相同的名字,在通过API获取缺陷信息时混用涉及project和stream的API。
解读
Project和stream是Coverity Connect管理软件缺陷时用到的两个完全不同的概念,有些用户在对Coverity Connect做配置时,并未对这两个概念太在意,导致后期在项目的缺陷管理上带来不少的麻烦。比较多见的是把Project和Stream理解成相同的概念,把Project和Stream名称设置成一样,这样在调用Coverity的Webservice API时任意选用关于project和stream的API,结果在获取时出现数据不一致。
在Coverity的官方文档中,对project和stream的定义如下:
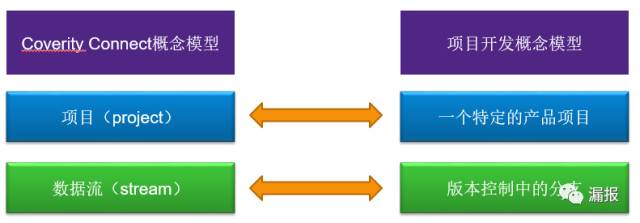
数据流(stream):快照(Snapshot)的有序集合。因此,数据流可以在一段时间内以及在开发过程的特定时间点提供有关软件问题的信息。
项目(Project):在 Coverity Connect 中,表示一组指定的相关数据流,用于全面展示代码库中的问题。
更形象化地来诠释上述定义,如下图,可以将项目理解成开发过程数据流对应为项目版本控制的一个分支,将项目理解成具体的一个开发项目。比如在开发过程中,我们会将项目拉出不同的分支来做功能开发(feature development)或者bugfix。在Coverity Connect中,不妨就把project命名为该具体的开发项目名,将Stream命名为具体的某一代码分支。这样在以后的缺陷管理上会更加方便。
误区五:
正式部署后未对检查器做有效筛选
典型误用场景
正式部署完Coverity后,直接沿用试用产品时的检查器(checker)来对项目的缺陷做扫描,检测出来不少缺陷,但每次检查提交都需要不少时间。
解读
为了演示Coverity的代码检测能力,Coverity在试用的时候都会应用一套默认的检查器做演示。在实际应用中,每个行业,每个公司对软件缺陷都有不同需求,如果不对检查器(Checker)做筛选,则Coverity将在对源代码检测时同时开启近200个检查器对代码做扫描。这样导致不但扫描的时间过长,而且检查出来的缺陷可能很多都是用户不需要的,再到后面对这些缺陷做诊断和管理则浪费了公司的开发资源。
推荐做法:
正式部署后,推荐与公司的开发组和项目管理组交流,选出符合公司和行业的检查器。将Coverity配置成准确服务于自身产品的源代码检查利器。
以上总结的用户在部署和使用Coverity时常见的五个误区:
过于频繁对源代码进行扫描和缺陷提交
未对Coverity Analysis和Connect做合理部署
把Connect当成一款代码管理工具
混淆Project和stream两个概念
正式部署后未对检查器(checker)做有效筛选
在公司实际部署和使用Coverity时,如果能对以上五个误区多加注意,相信必将在日后的Coverity维护和管理中消除不少麻烦,也能进一步提高对软件安全缺陷的管控,进而提高软件质量。
关于Synopsys
Synopsys(Synopsys, Inc.,纳斯达克股票市场代码: SNPS)致力于创新改变世界,在芯片(Silicon)到软件(Software)的众多领域,Synopsys始终引领和参与全球各个科技公司的紧密合作,共同开发人们所依赖的电子产品和软件应用。Synopsys 是全球排名第一的电子设计自动化(EDA)供应商和全球排名第一的半导体接口IP供应商,同时也是软件质量和安全解决方案的全球领导者, 位列世界第15大软件公司,并荣选美国标准普尔500指数成分股龙头企业。Synopsys总部位于美国硅谷,成立于1986年,目前拥有11400多名员工,分布在全球100多个分支机构。2017年财年营业额预计26亿美元,拥有2600多项已批准专利。作为半导体、人工智能、汽车电子及软件安全等产业的核心技术提供商与驱动者,Synopsys的技术一直深刻影响着当前全球五大新兴科技创新应用:智能汽车、物联网、人工智能、云计算和信息安全。
自1995年进入中国市场以来,Synopsys已在北京、上海、深圳、西安、武汉、南京、厦门、香港、澳门九大城市设立机构,员工人数已超过1000人,建立了完善的技术研发和支持服务体系,秉持“加速创新、推动产业、成就客户”的方针,与产业及合作伙伴携手共进、共同发展,成为中国半导体产业快速发展的优秀伙伴和坚实支撑。
